有人觉得为了支持两阶段提交,而对性能和可用性造成的影响,这样的代价太高。而我们却认为把这些滥用事物的性能问题留给应用程序员,而不是让他们去处理事物一致性的问题。 —James Corbett et al., Spanner: Google’s Globally-Distributed Database(2012)
闲聊事务
事务被创造本来就是为了简化编程模型。让下层数据库对于并发的处理,上层应用尽量够忽略潜在的并发问题。 但是也不是所以应用都需要事务,为了更好的性能或可用性,选择弱事务安全级别甚至完全抛弃事务也是存在的,这里面有着复杂的选择权衡。
说到事务那么ACID肯定是难以避开的话题。
- 原子性(atomicity)表现为事务中的所有操作要么全部完成,要么全部不完成(回滚),不会出现中间状态。
- 一致性(Consistency)表现为在事务开始前和结束后完整性约束(不变量)不被破坏。
- 隔离性(Isolation)表现为事务之间相互独立,互不影响。
- 持久性(Durability)表现为事务结束后对数据的修改是持久化,不丢失的。
数据库达到ACID所描述的那么必然很安全可靠的。但是,如同上面所说的,很多从性能和可用性角度出发,不一定支持完全隔离。例如很多NoSQL数据库,有的甚至不支持事务。突出某一方的能力势必有其他方面有所损失。这里本质上就是一个权衡利弊的过程。但是现实状况是在应用层做事务非常困难,因此很多NOSQL也开始支持不同级别隔离的事务。
麻烦的事务
串行事务
事务串行执行最容易理解,事务排队挨个执行,之间不存在任何影响,其结果必然是最为正确的 。但是其缺点非常明显,如果有事务执行时间过长,那么就会导致其他事务长时间的等待影响性能。因此出于性能考虑我们需要并行。然而并行必然带来数据的冲突,所以我们需要相应的技术来解决冲突。
可串行化事务
如果串行调度S和并行调度S1,对于相同的数据库初态,都有相同的效果,那么认为调度S是可串行化的(serializable schedule)这是书中关于可串行化事务的定义 举例来说:事务T1,T2,T3都为X写入一个值,T1 T2写入X前还都为Y写入值 。其串行如下:
S’:w1(Y)w1(X) w2(Y) w2(X) w3(X)
而也有可能是
S:w1(Y)w2(Y) w2(X) w1(X) w3(X)
S调度看似好像不对啊,特别w1(Y)w2(Y) w2(X) w1(X) T1 T2交错执行,但是不一致最终都被T3将X值覆盖。从而 S和S’是等价的,因此S是可串行化事务。
冲突可串行化事务
在上面的调度S中w1(Y)w2(Y) w2(X) w1(X) 是有问题的,因为写入Y时,T1先于T2,而写入X时候T2先于T1,最终数据不一致了。从上面串行化事务可以看出有问题的调度最终状态却和串行是一致的,那对于程序来说需要找到一种易于操作的判断方法来计算调度是否等价于串行。这个方法就是冲突可串行事务。
冲突
这里的冲突的意思是两个操作不同顺序导致不同结果,并不是说有冲突数据就不正确。 冲突有三类
- Read-Write conflict
- Write-Read conflict
- Write-Write conflict
我们假设两个不同的事务(T1,T2)同一时间做以下事情:
- T1,T2同时读取数据,即便相同数据,这里不存在冲突。
- T1读取数据,T2写入数据,只要是不同的数据,也不存在冲突。
- T1,T2同时写入不同数据,也不存在冲突。
- T1读取和T2写入相同数据,存在冲突。
- T1和T2同时写入相同数据,存在冲突。
我们能够发现,只要俩事务同时涉及一个元素,并且存在写操作,那么必然冲突。
冲突可串行
倘若调度S不同事务中的俩操作不冲突,那么就可调换先后顺序。通过一系列的调换后如果成为串行调度,那么S就是冲突可串行化。
通过绘制优先图更好理解。优先图表示事务先后顺序,有环出现说明事务先后顺序发生了变换,例如 w1(Y)w2(Y) w2(X) w1(X) T1先于T2写Y,却后于T2写X。而所谓串行就是T1事务全部操作先于/后于T2,因此只要优先图有环出现就说明无法串行化。
调度事务
从下图可以看出冲突可串行化调度是可串行化调度的子集。
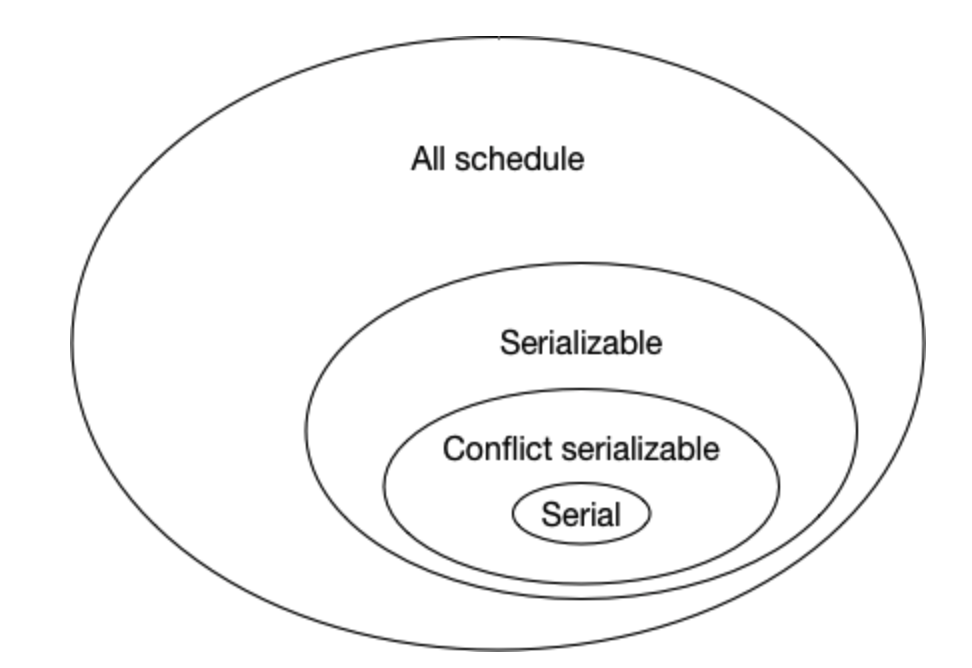
现在隔离级别中常说的可串行化(serializable),其实是就是指冲突可串行化(conflict serializable)。因为可串行化实在太不好验证了。我们想象一下,有一个调度,在把数据库数据搞得乱七八糟,可是最后却有几个写操作将数据库不一致的状态置为一致。这个调度得是多么的危险啊,万一最后置为一致的事务abort了呢?虽说这个调度是差劲,但是却能让数据库最终是一致的。
实现串行
数据库中处理冲突的的大方向有二,分别是:
- 主动避免冲突。数据上锁悲观对待冲突,认为冲突容易发生。
- 不理会冲突发生,最终检测并解决冲突。认为冲突不容易发生,但是一旦发生就是麻烦事。因此对于不容易发生冲突的系统,这能够显著提高吞吐。例如大量读操作,很少写操作的系统。
实现串行目前方法有二
- two-phase locking(2PL)这个一般数据库书籍都会介绍
- Serializable Snapshot Isolation (SSI)这个方法是在2008年才被提出,在MVCC基础上的提升。
弱隔离级别
串行固然很秀,但是现实世界时间是宝贵的。甲方银行爸爸肯定指着工程师的鼻子质问:我TM就查个存款怎么等了半天还不出来,是我钱丢了吗??工程师战战兢兢回答:因为….有人一直在取你的钱,你账户限额,他都取了半小时还没结束! 甲方爸爸:WTF!!
ACID之间不是完全独立没有关系,但是关于原子性和持久性这两点数据库一般都是必须支持的。而一致性和隔离性存在一定的权衡空间,因此才有了不同的弱隔离等级。 下面简单介绍一下隔离级别。
Read Uncommitted
其他事务未提交的都能读取。
Read Committed
可以读到其他事务提交的数据。这是数据库隔离的最低级别。包括以下内容:
- 你只能读到已经提交的数据,没有脏读。
- 你写入覆盖已经提交的数据,没有脏写。
Repeatable Read
同一个事务中你多次读取同一数据永远不改变,及时实际上数据已经被其他事务更改了,而恰恰是看不到这种改变,带来幻读或者write skew问题。
Serializable
串行读写,最高级别。每个事务顺序执行,绝对的正确。因此没有考虑冲突的必要了。
上面四个隔离级别是在ANSI SQL-92的标准级别,由于制定标准的年代,那个时候甚至还没有MVCC这样的技术,因此导致事务隔离级别完全是按照锁的实现来制定的,其描述的问题都是上锁中可能出现的问题。因此很多批评指出了ANSI隔离级:没有做到实现无关。导致标准在不断进步的技术面前不再标准,反而搞得大家云里雾里。
一直到2000年,Ayda 的一篇论文终结了隔离级别的讨论,提出了完全实现无关的隔离级别定义。回归到了事务的本质,通过事务之间的依赖关系,来定义完全实现无关的隔离级别
混乱的现实
学术界经过了数十年的讨论,终于找到了一个如何描述事务隔离性的满意答案。但是,工业界真正实现的数据库,却是另外一幅景象…
而且即便是同一级别在不同数据库中也是有不同的实现。
我只是想存一条数据为何如此困难?或许NOSQL中不少对事务的排斥也是程序员一种无声的宣泄吧!太TM复杂了。
什么是正确
那到底什么样的隔离是正确?串行肯定是正确,甚至是绝对的正确。因此冲突可串行也是正确的,而且上文中的糟糕的调度其结果也是正确。
只要不是串行,都有着不同的”错误“。因此不同隔离级别有着不同的正确范畴,在同一级别下有着而无法避免的”错误“。不能因为在该级别下,出现了不一致就说是”错误“。这里的”错误“是级别所固有的,是为了性能而选择放弃的。因此选择不同的级别,意味着接受相应的”错误“。
#事务小问题
不管现实世界多么烦扰,划分级别多么混乱,但是当了解清楚解决的问题后,一切都会清净下来。
问题一
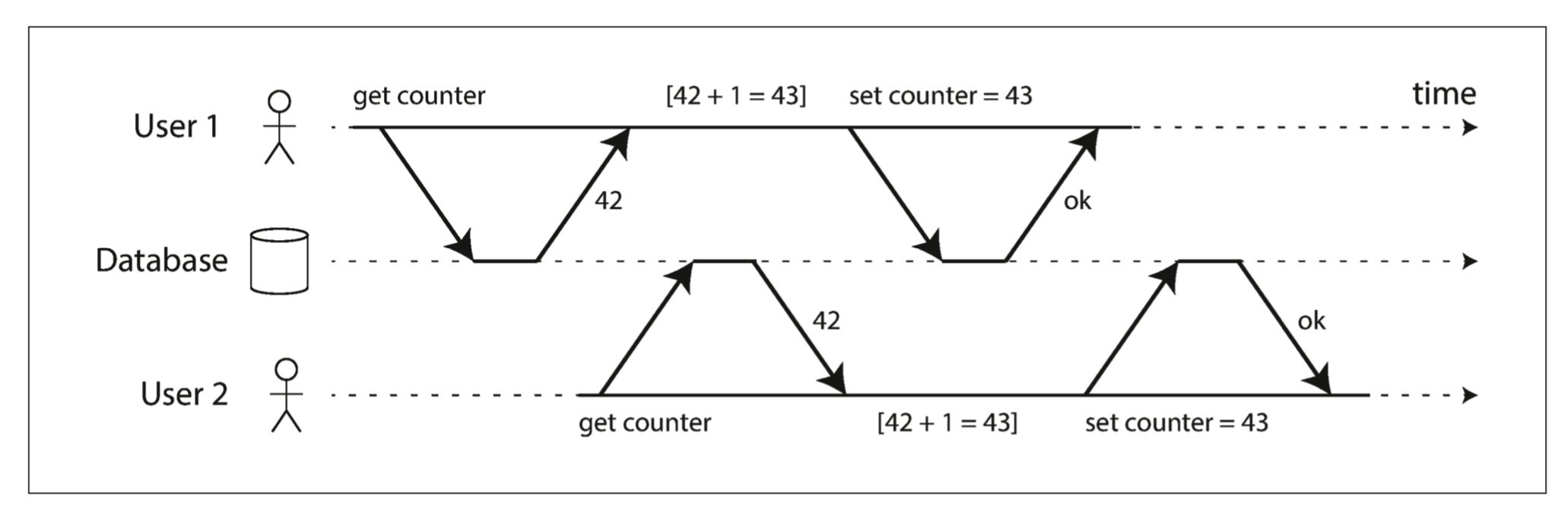
两个事务之间出现竞态,于多线程计算中的问题一样。针对这个问题需要串行的隔离级别才能解决。 当然对于问题自身,可以通过数据库的CAS操作来完成,不一定说需要改变数据库隔离等级。
问题二
这是一个的脏读(dirty read)场景。一个事务读取了另外一个事务还未提交的数据。
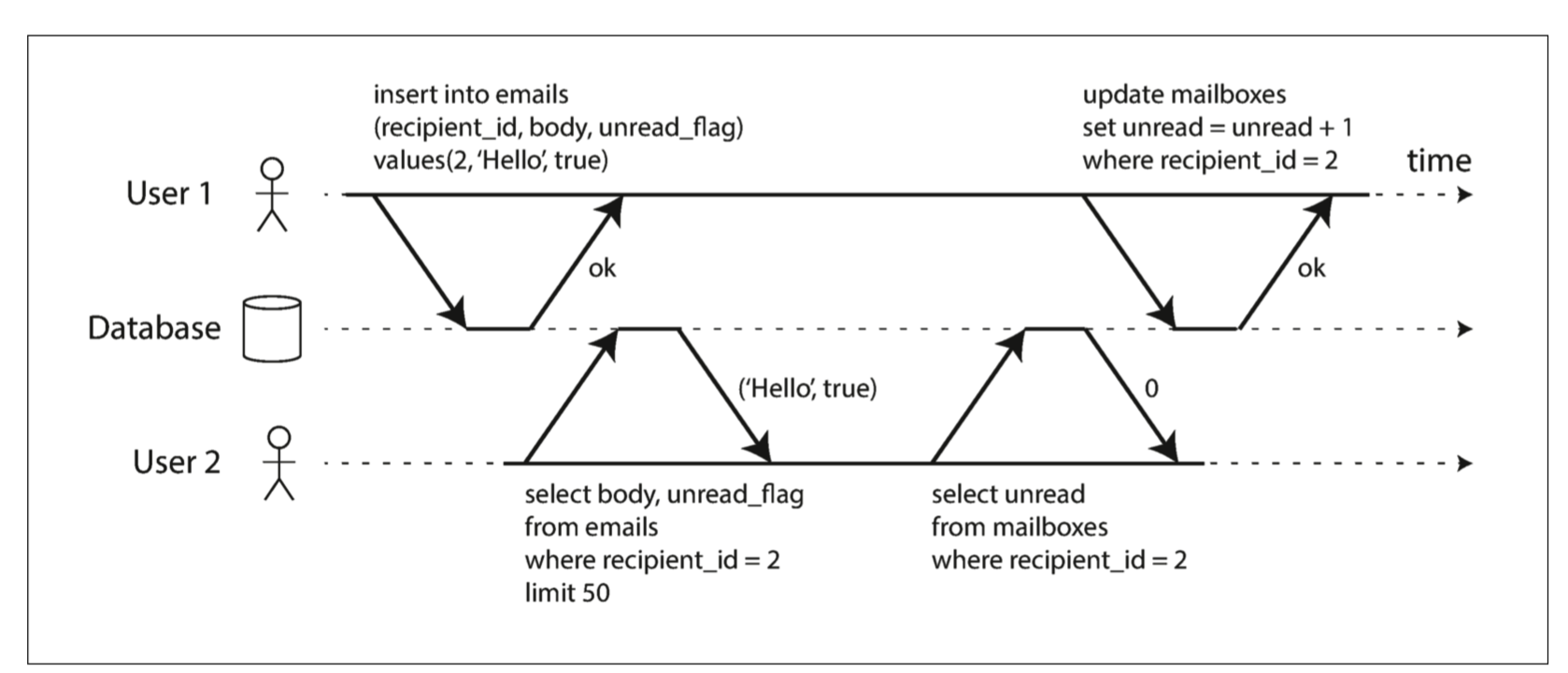
问题三
这是一个的脏写(dirty writes)场景。一个事务覆盖了另外一个事务还未提交的数据,最终数据库不一致。
问题四
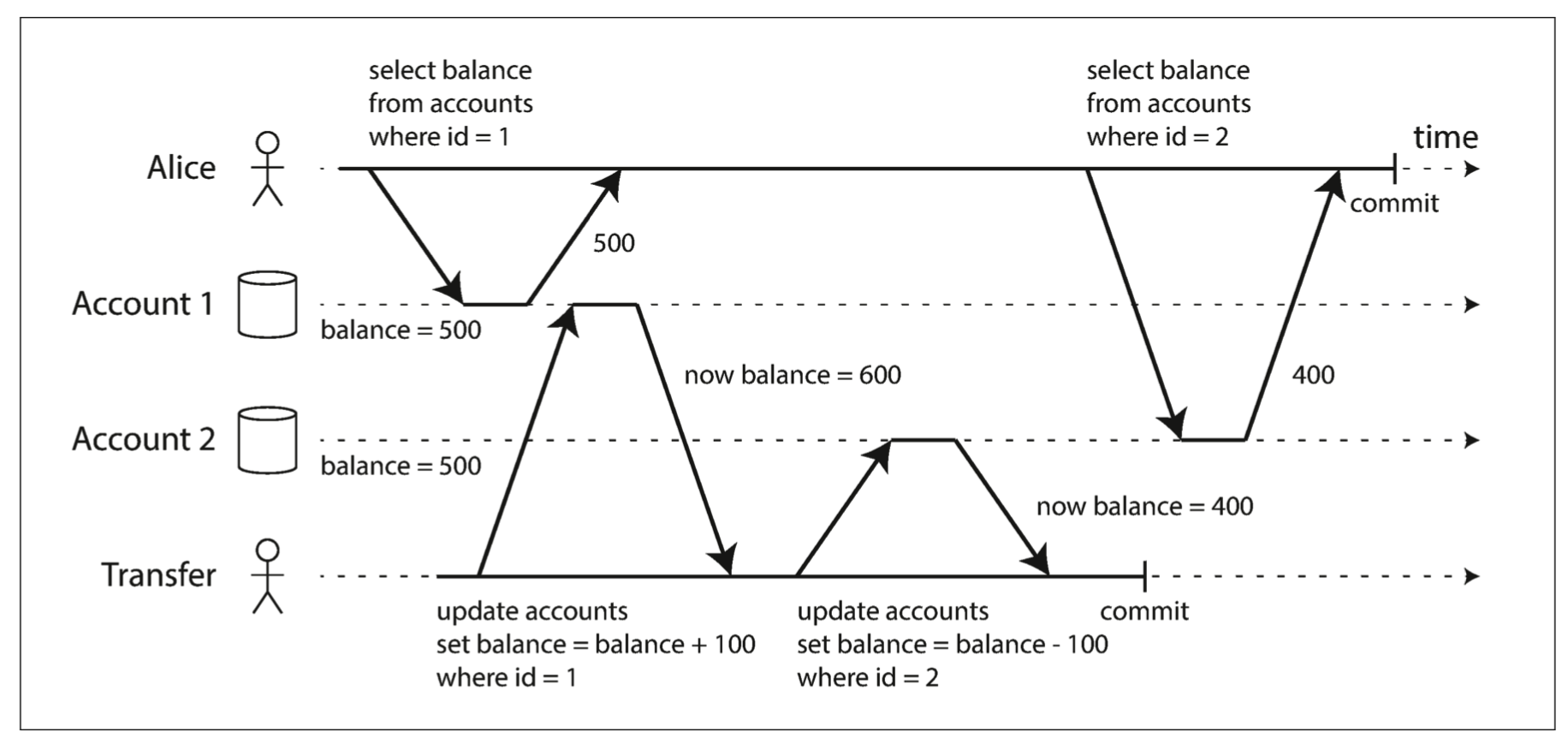
不可重复读,或者read skew。这里的问题在于一个事务开始后,读到了另外一个事务的更新数据,导致该事务前后数据不一致。
我们仔细思考一下问题二三四其出现的根本原因。一个事务影响到了另外一个事务。那为了并行又事务之间又不相互影响的最好办法就是”平行宇宙“(snapshot isolation)或者其实现MVCC。各个事务在各自的世界中执行。
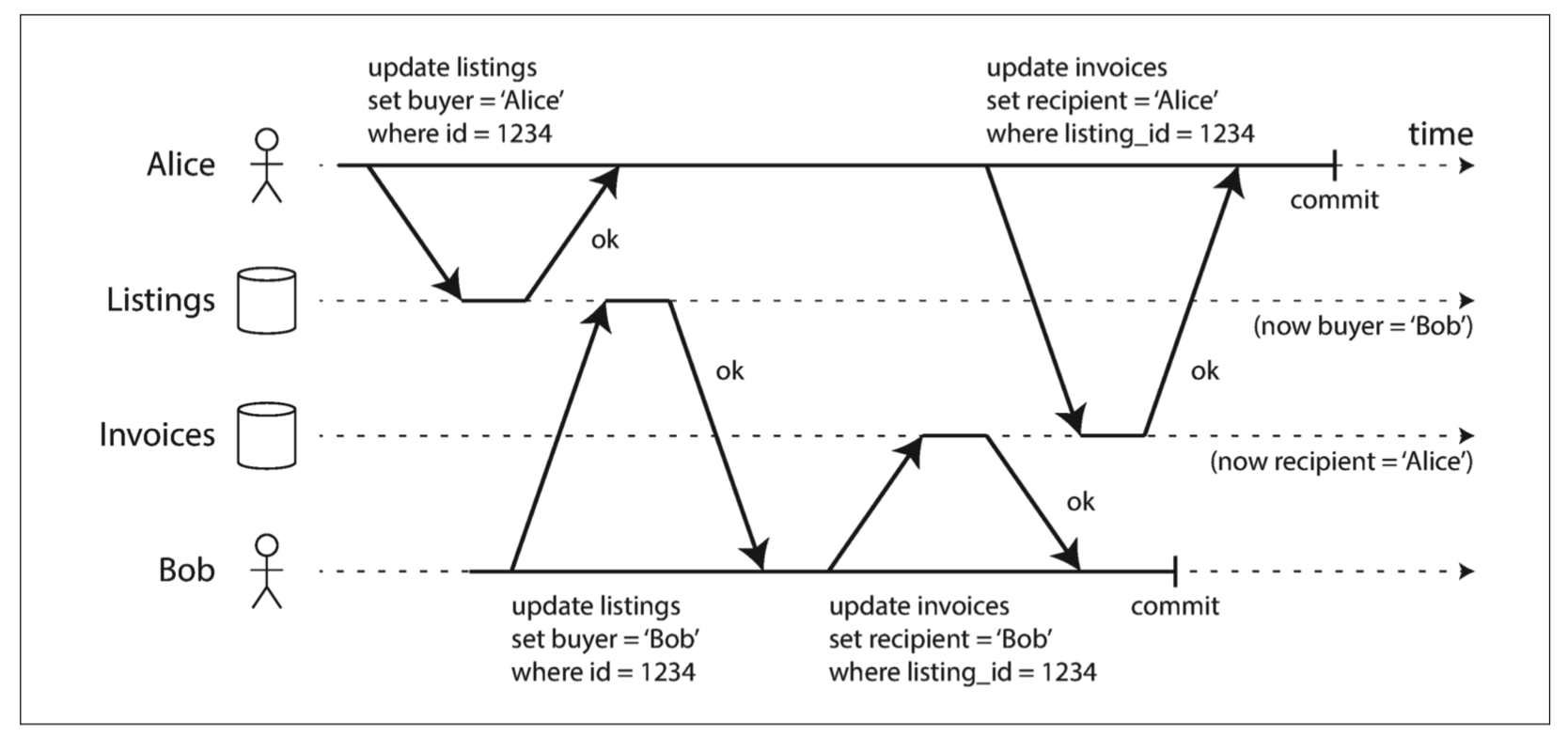
问题五
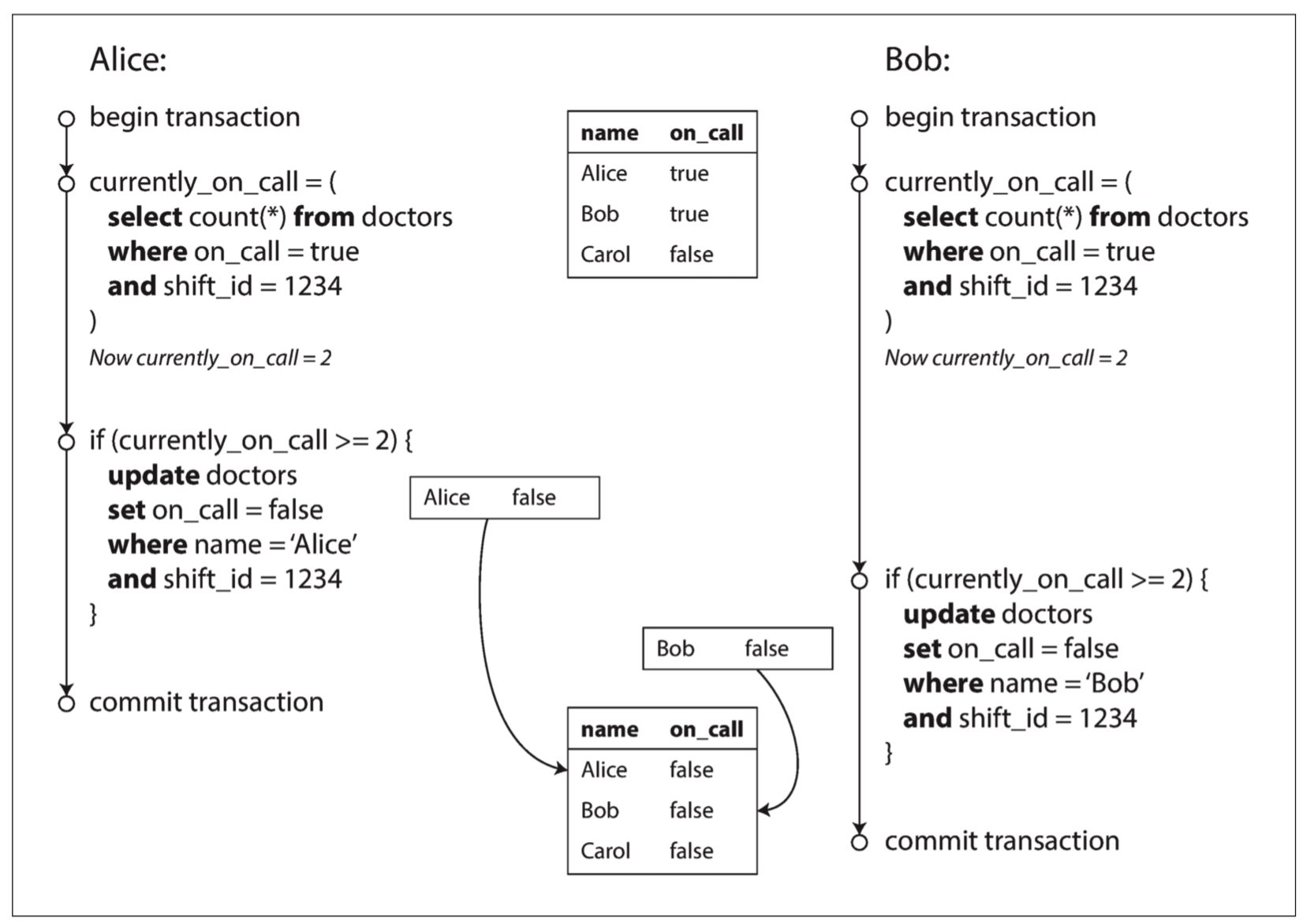
Write Skew或者Phantoms的场景。与问题一属于同一个问题,操作所依赖的前提条件,在写入前不再成立,本不应该执行的操作却依然执行。
但是到这个问题这里,发现”平行宇宙“失效了。因为各自世界中的状态最大的特点就是相互隔离,所以可能是落后于”主宇宙“的,因而自身宇宙状态来更新”主宇宙“状态必然是容易出错的。 这个问题通常需要2PL做串行。当然在”平行宇宙“(Snapshot Isolation)基础上最新研究出了”串行平行宇宙“(Serializable Snapshot Isolation)。在”平行宇宙“基础上给数据增加了更多的状态,在提交”主宇宙“的时候确保所依赖的状态是最新的未被更改的。
笔记最后
这篇blog从3月份开始写的,到今天已是7月。并不是因为事务有多复杂,而是事务真是比较混乱,有一种道理我都懂可总是说不清的感觉。期间应该尝试写过多次,都有种不知从何说起的感觉,直到今天下定才决心必须写完,当然其中很大一部分原因是因为近来反复思考隔离问题的本质,把其中很多方面简化串联了。此外文章结构上我受到可串行化(Serializable):理想和现实的不小启发。