文中代码基于Spark 版本2.3.0
目前Spark 在 Standalone Mode 下,所支持的 Task 调度策略有 FIFO 和 FAIR 两种策略。
RDD 执行流程
在介绍Capacity Scheduler之前,粗略说一下 RDD 如何执行的。
- RDD 对象中包括 dependency 属性,表明当前 RDD 与父 RDD 的依赖关系。
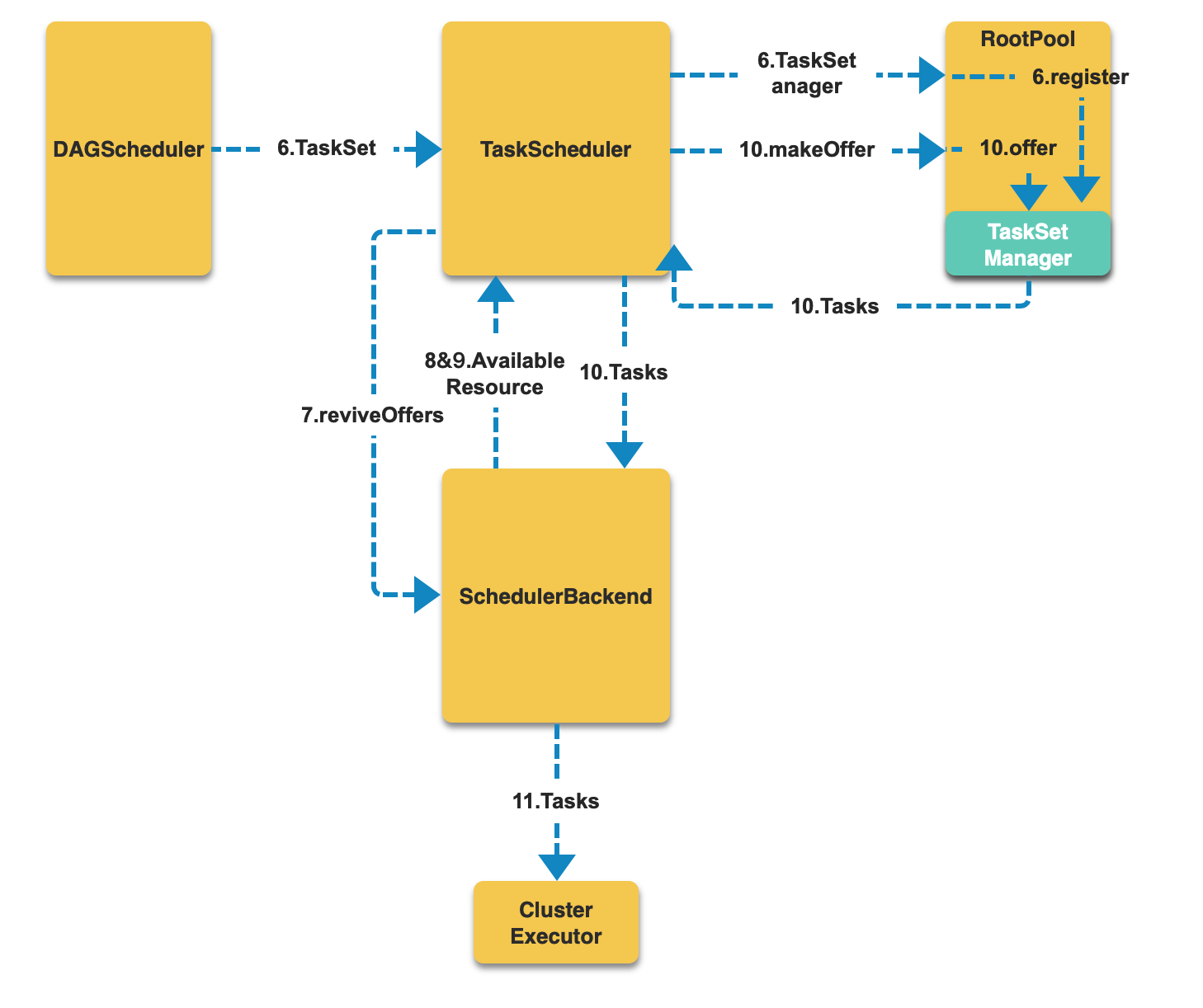
- DAGScheduler 利用dependency依赖关系将 RDD 按照宽依赖,也就是需要进行 shuffle的依赖作为边界,划分成为一个个相对独立的 stage。
- 每个 stage 必须确保父 stage 完成后才能进行
- DAGScheduler提交第一个没有父依赖的 stage
- 该 stage 依据 partition 数量会被划分成为不同 Tasks,并构造一个 TaskSet
- 该 TaskSet 交由TaskScheduler,TaskScheduler利用TaskSet构造一个TaskSet Manager对象,并注册此 Manager 对象到相应的 Scheduler (RootPool)中(如果 Fair 模式)
- TaskScheduler 这时候会调用SchedulerBackend的reviveOffers方法
- SchedulerBackend主要负责维护调度系统的资源,SchedulerBackend可以获得当前系统有多少可用资源。
- SchedulerBackend将可用资源信息交给TaskScheduler,
- TaskScheduler通过makeOffers方法获得需要执行的 Task。实现上面TaskScheduler进一步将资源信息交给 RootPool 对象,RootPool最终会将选择 Task 的工作交到TaskSetManager中,TaskSetManager选出需要提交的 Task 返回(策略产生效果的步骤)
- SchedulerBackend提交 Tasks 到 Executor 中执行
- Executor执行完成后,调用statusUpdate方法,发送/StatusUpdate/消息到SchedulerBackend
- 调用TaskScheduler的statusUpdate方法,进行状态更新
- TaskScheduler会调用对应的 TaskSetManager 进行更新状态。
- TaskSetManager会通知DAGScheduler更新相应状态,如果任务 Stage 完成,DAGScheduler会提交下一个 Stage,跳到第4步继续执行。
- SchedulerBackend会继续执行makeOffers确保余下的 Task被执行。
至此一个 RDD 的执行全过程就完成了。 这其中6-11步骤是调度的核心步骤,需要优化定制的可以结合下图深入了解。
如果只是需要了解调度过程,其实可以一句话简单概括
- 注册需要执行的任务,获得当前系统可用资源,按照任务策略选出执行的任务,最后交给集群执行。
源码分析
首先我们从CoarseGrainedSchedulerBackend对象开始。CoarseGrainedSchedulerBackend 提供了系统可用资源信息,然后交个调度器获得可执行的任务,最终交给 executor 执行。具体我们看下面对代码,已经加了注释。
private def makeOffers() {
// Make sure no executor is killed while some task is launching on it
val taskDescs = CoarseGrainedSchedulerBackend.this.synchronized {
// 获得当前集群可用的 Executors
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
//做一些对象转换,主要目的在于任务执行有 locality 的要求。
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
//交给Task调度器获得需要执行的任务描述
scheduler.resourceOffers(workOffers)
}
if (!taskDescs.isEmpty) {
//执行任务
launchTasks(taskDescs)
}
}
上面的代码是执行任务的主要代码,但是关于任务是如何选择的我们需要进一步深入 TaskScheduler 中了解。下面的代码是TaskSchedulerImpl#resourceOffers 的精简后的。
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
//rootPool 在注册的 TaskSetManager 中依据优先级进行排序
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
//在 TaskSet 中以及当前资源的 locality来确认执行的 tasks
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
上面的代码是获得需要执行的 Task 的核心代码。这篇Blog的主要目的在于提供一个整体的结构,因此不会再继续深入。如果需要定制功能,那么必须要深入到获得 Task 的细节逻辑。这里不多赘述。
总结
根据上述的调度逻辑中可以看出,Spark 的调度算法还是非常简洁高效的。不过我们也能发现一些,主要在于结构有点耦合了,在 Standalone mode 基础上增加一个调度策略难度不小,而且对于代码入侵较高。主要体现有两点,第一点,非常依赖Schedulable 的 Pool 的实现,导致难以增加 Schedulable 的新实现。第二点,Pool 的参数以属性的形式呈现,导致增加一个参数必须要改动代码。上述两点比如导致,增加一个自定义的调度策略,除了处理调度的逻辑外,还要改动 Pool 的代码。当然这些问题在没有扩展需求的时候,都是微不足道的。这里没有批判更没有鸡蛋里挑骨头,只是说一下在自定义调度时候的真实感受。